Introduction
Modern dynamic light rendering techniques, such as Clustered shading, are very impressive if you want thousands of lights, and after implementing my own method for rendering scenes with hundreds of lights, I got to thinking about shadows…
What good are all these lights unless many or all of them are casting shadows?
Eye Candy
In this scene I have about 120 lights. Each light is omni-directional, so each one uses 6 views to render a cube shadow map, so that is 600+ shadow maps being rendered. All objects are casting shadows. The shadow map resolution is scaled with distance from the camera in order to fit in memory.
You can see the shadow maps being rendered in the bottom left.
So… I wanted hundreds of shadows and I set out to solve the problem. I was very impressed by earlier attempts such as Imperfect Shadow Maps and the ManyLods Algorithm but both suffer from holes when rendering large views, and hence, are not suited for rendering high resolution shadow maps. ManyLods can also end up with very deep trees because of the number of points required to represent large triangles.
This led me to a small eureka moment when I realized that there is no point in using a point representation: You can have a BVH of triangles and still get the benefits that the ManyLods algorithm brings – being able to render a node when its projected area is small enough that its children can effectively be ignored, allowing the algorithm to skip large sections of costly BVH traversal.
With a triangle BVH you still have a hierarchical representation that can be used to splat points into the view buffers if the projected area of the BVH node becomes smaller than a pixel. The advantage is that when the traversal gets down to the triangle level you can stop traversal and render the triangle directly to the view buffer – even if the node still has a large view-space projected area. This is where ManyLods would carry on traversing down the tree, potentially to the highest detail level points/surfels, as it requires all nodes that are drawn to either be leaf nodes or to be smaller than some metric in view space.
Another disadvantage of pure point based methods is that on modern hardware, rendering points is generally more expensive than rendering triangles, so you only really want to render points if they are going to save you from rendering many small sub-pixel sized triangles.
I call the following algorithm “Many Perfect Shadow Maps” or ManyPSMs for short, as a homage to the Imperfect Shadow Maps and ManyLods algorithms.
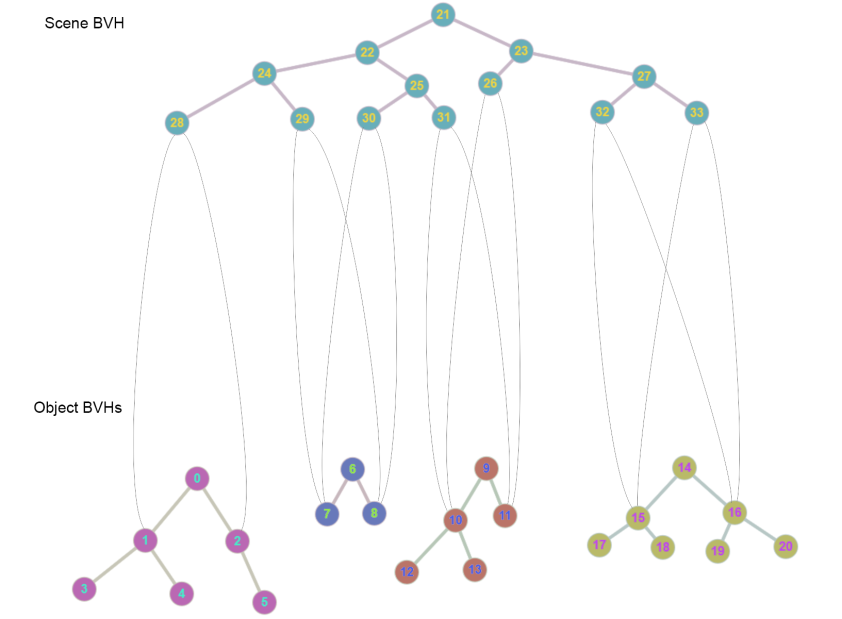
BVH GPU Structure
The scene and object instance BVHs are all packed into a single GPU Buffer. Object vertex data is stored in a separate buffer.
After all objects’ BVHs are loaded (they are generated offline), they are packed, one after the other, into the GPU Buffer, keeping track of their root nodes’ child indices. Leaf nodes store triangle indices into the vertex buffer. This part of the buffer is static.
During run-time, the dynamic scene BVH is updated and packed into the dynamic part of the same buffer. While packing the scene BVH, if an object instance is encountered, its world transform is packed into an instance buffer, the index to which is stored in the packed scene BVH node, along with child node Indices obtained from the object instance’s static BVH’s root node’s children – allowing a single and simple traversal kernel to traverse the static and dynamic parts of the tree.
The Algorithm
So the algorithm is very similar to ManyLods, iteratively traversing the scene BVH for each view in parallel in a compute shader. This is done using a similar Node-View pattern (except it it extended to handle object instances). So the Node-View stores a Node Index, a View Index, and an Object Instance Index. During each iteration, or compute dispatch, one level of the tree is processed, filling buffers and generating indirect dispatch arguments for the next iteration.
First, the initial Node-Views for the scene are created in a GPU Buffer, one initial Node-View is created for each view in the scene, containing that View Index (1 to n) and Index of the root node of the Scene (for example, 21 in the image above) BVH. The Object Instance Index is initially set to 0xffffffff.
A compute shader is then dispatched, once for each level of the tree. Each thread loads a Node-View, and performs one of five tasks:
- Apply Object Instance Transform
If a Node contains an object instance, the compute kernel needs to load the instance transform and apply it to the view transform. The object instance index is also propagated to any subsequent Node-View traversal steps - Cull
Nodes are culled if they are outside of a cone wrapped around the View’s frustum. - Draw Triangle
If a node contains a triangle, the triangle indices are pushed into an index buffer for later rendering to a triangle splat buffer. - Draw Point
If a node’s estimated projected area is less than or equal to one pixel, it is pushed into a list of points for later rendering to a point splat buffer. - Traverse
If a node can’t be drawn or culled, its children are pushed into a list of Node-Views for processing in the next iteration.
Splatting
The shadow maps are splatted/rasterized simultaneously with a single draw all to splat all triangles into all views, and a single dispatch to splat all points into all views. The splatting happens on a large texture atlas containing all the shadow maps.
A compute shader is dispatched to splat all the points into views on the point splat buffer. Then a Draw call is made to splat all of the triangles into all views in the triangle splat buffer. Triangle view-clipping is currently done in the pixel shader, but it would be better to move it to a pre-process or geometry shader, as clipping in in the pixel shader is inefficient.
After this, a compute shader is used to merge the results and copy them into cube map arrays for the lights to address while rendering.
Here is another video before the shadow map filtering was fixed:
Future Improvements
- Triangle splatting: triangles need to be clipped to each view, this is currently being done in the pixel shader, but should really be done in a geometry shader or as some pre-process.
- Shadow map filtering: Shadows are currently unfiltered, I would like to try a tri-axis cube map blur.
- Better Shadow map representation: I’m currently using VSM, I would like to try MSM or something else.
- Optimizations: There is a lot of optimization that could be done to the shaders and render code to improve performance.
- Blend between shadow resolutions using mip-maps.
ManyLods & Imperfect Shadow Maps
If you were interested in these, here are videos for the ManyLods and Imperfect shadow maps algorithms.
Update 1, 27 March 2019: Triangle View-Clipping in the atlas is now done with SV_ClipDistance
Update 1, 27 March 2019: Added shadow map filtering with tri-axis cube map blur.

To clip a triangle to a view, one way to do it is to use custom clip planes. If each triangle knows the view it “belongs” to, it can set up four clip planes in the VS and have the hardware clip it (without needing GS, which is very slow)…
Basically if you know that for a given triangle this should be true for the left edge (if x and w is the projected coordinate in the VS): x/w >= a
Where ‘a’ is the left edge of the sub-view in NDC space, then you can rewrite this as x >= a*w = x – aw >= 0, which you can then stick into the x component of an SV_ClipDistance. Then do the same for the other three edges (taking up four components of one of the SV_ClipDistances) and the hardware will clip pixels that have a negative value for either edge.
LikeLike
Hi, thanks for the comment. This is a good point, and I already implemented this a while ago using SV_ClipDistance, but it doesn’t really improve performance, as most of that is down to traversing the tree structure.
LikeLike
Hi, this tech. looks very promising, even fighting against recent ray cast’s shadow casting solutions 🙂
The final cube array you talk, which receive this dynamic atlas (via a copy), is it allocated for the worst case (maximum resolution for all instances of cubes) ?
And you manage selecting compute LOD for each cube in that array (both for the write and the sample) ?
I suppose your lights (all omni ?) have same radius, then same shadow requirements.
What about supporting (more realistic) variable light (then shadow) radius ?
(I mean some bigs lights, usually spots, and many local omnis)
A better solution would then be to atlas directly your cube’s faces (in your Texture2D) rather than building cubes, which allows to change resolution per face (face toward camera needs more pixels).
But I think this method still is not enough to handle the classic ‘dual frustum’ issue with shadow mapping, a solution for directionnal is pssm/cascade, but for omni/spots, that looks more complex.
Could you comment on that please ?
Thanks
LikeLike
Hi!
The lights all have their own radius, and it can also change dynamically. The lod calculation could be better, and I also need to blend between lods to remove the popping.
There are a few final cube arrays – one for each view resolution, but I cant allocate worst resolution for maximum number of views, as that would be too much memory. I allocate arrays like this:
340x 16
340x 32
170x 64
42x 128
10x 256
And then I assign each light to a cube map size based on the light’s projected screen space area.
I have also thought about implementing octahedral mapping.
I don’t know what the “classic ‘dual frustum’ issue with shadow mapping” is that you are referring to.
LikeLike
I was referring to ‘duelling frusta’ (http://jankautz.com/courses/ShadowCourse/02-ShadowMaps.pdf)
(shadow map aliasing worst case).
Octahedral mapping could be a nice idea for big lights to cull/reduce shadow regions (per light).
Thanks for the cube reso. figures, IMO cube of 256 may be low for big light when you look it’s shadow close to light’s radius. Maybe things can be ok with a high quality filter.
LikeLike